Инструкция
Извлечение текста из отсканированного PDF
Отсканированный PDF это, по сути, фотография страницы: текст выглядит правильно, но его нельзя выделить, найти или скопировать, потому что он хранится в виде пикселей, а не символов. Оптическое распознавание символов (OCR) превращает эти пиксели обратно в настоящий текст, который вы можете вставить в документ, найти через Ctrl+F или проиндексировать на будущее. В этом руководстве используется OCR-движок на устройстве, поэтому ваш скан никогда не покидает компьютер.
Шаг за шагом
- Откройте инструмент OCR и перетащите в него отсканированный PDF или файл изображения. Инструмент принимает PDF, PNG, JPEG, WebP и ряд других форматов изображений. Для многостраничного скана формат PDF самый удобный единый источник ввода.
- Выберите язык текста в документе. По умолчанию используется английский. Выбор правильного языка помогает OCR-движку подобрать нужные формы символов и повышает точность на буквах с диакритикой и пунктуации, специфичной для конкретного языка.
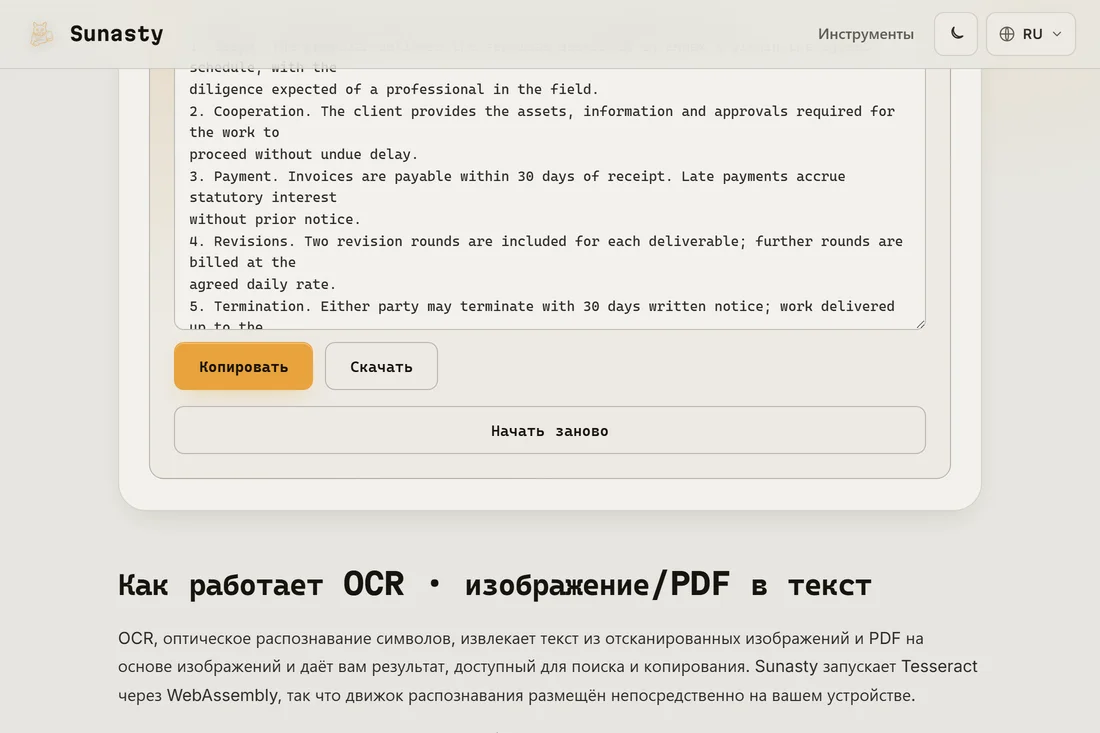
- Нажмите «Выполнить» и дождитесь завершения OCR. Движок (Tesseract, скомпилированный в WebAssembly) работает целиком в браузере. Обработка одной страницы A4 занимает несколько секунд на современном устройстве. Результат это обычный текстовый файл, который вы можете скачать и из которого можно копировать.
Как качество OCR зависит от качества скана
Точность OCR в первую очередь определяется качеством исходника. Чистый скан в 300 DPI печатного документа (вывод лазерного принтера или копира) даст почти идеальный результат. Размытое фото с телефона, снятое под углом при плохом освещении, даст гораздо худший вывод с неправильно распознанными символами, слипшимися словами и пропущенными строками. Если результаты плохие, попробуйте улучшить исходный скан: снимайте строго фронтально, при хорошем свете, держа страницу ровно. Инструмент выравнивания PDF может выпрямить слегка повёрнутый скан перед запуском OCR.
Что делать с извлечённым текстом
Вывод это обычный текстовый файл с распознанными символами в порядке чтения. Вы можете вставить его в текстовый редактор, найти в нём что-то, перевести его или использовать как отправную точку для редактируемого документа. Для PDF с возможностью поиска (исходное изображение страницы с наложенным невидимым текстовым слоем) вы обычно использовали бы специализированные настольные программы вроде Adobe Acrobat или OCRmyPDF: инструмент на устройстве здесь выдаёт только обычный текст, что и нужно в большинстве случаев.
Инструменты из этого гайда
- OCR · изображение/PDF в текст Извлекайте текст из отсканированных изображений или PDF полностью в вашем браузере, работает офлайн, без загрузки.
- PDF в изображения Конвертируйте каждую страницу PDF в PNG или JPG прямо в браузере.
- Сжать PDF Уменьшите размер PDF-файла за счёт безвозвратной оптимизации внутренней структуры без загрузки.
Частые вопросы
Загружается ли мой скан на удалённый сервер?
Нет. Tesseract скомпилирован в WebAssembly и работает прямо во вкладке браузера. Языковая модель (около 4 МБ для быстрой английской модели) скачивается с этого сайта один раз, а затем остаётся в кэше для офлайн-использования. Ваш файл считывается с локального диска и обрабатывается в памяти: он никогда не отправляется на сервер. Это особенно важно для отсканированных договоров, медицинских документов или личной переписки.
Почему вывод OCR на моём документе несовершенен?
Ошибки OCR возникают из-за качества скана (низкое разрешение, размытие, перекос, тени) или из-за необычных шрифтов и вёрстки. Сначала попробуйте инструмент выравнивания, если страница не идеально ровная. Для рукописного текста точность Tesseract значительно падает: он обучен на печатных символах, а не на рукописном письме. Для смешанных документов (печатный текст плюс рукописная подпись) печатные части обычно распознаются правильно, а рукописные будут искажены или пропущены.