Så gör du
Extrahera text från en skannad PDF
En skannad PDF är i grunden ett fotografi av en sida: texten ser rätt ut men kan inte markeras, sökas i eller kopieras eftersom den lagras som pixlar, inte tecken. Optisk teckenigenkänning (OCR) omvandlar dessa pixlar tillbaka till verklig text som du kan klistra in i ett dokument, söka i med Ctrl+F eller indexera för senare. Den här guiden använder en OCR-motor på enheten, så din skanning lämnar aldrig din dator.
Steg för steg
- Öppna OCR-verktyget och släpp in din skannade PDF eller bildfil. Verktyget tar emot PDF, PNG, JPEG, WebP och flera andra bildformat. För en flersidig skanning är PDF-formatet den smidigaste enskilda inmatningen.
- Välj språket för texten i dokumentet. Standard är engelska. Att välja rätt språk hjälper OCR-motorn att välja rätt teckenformer och förbättrar träffsäkerheten på accenterade bokstäver och språkspecifika skiljetecken.
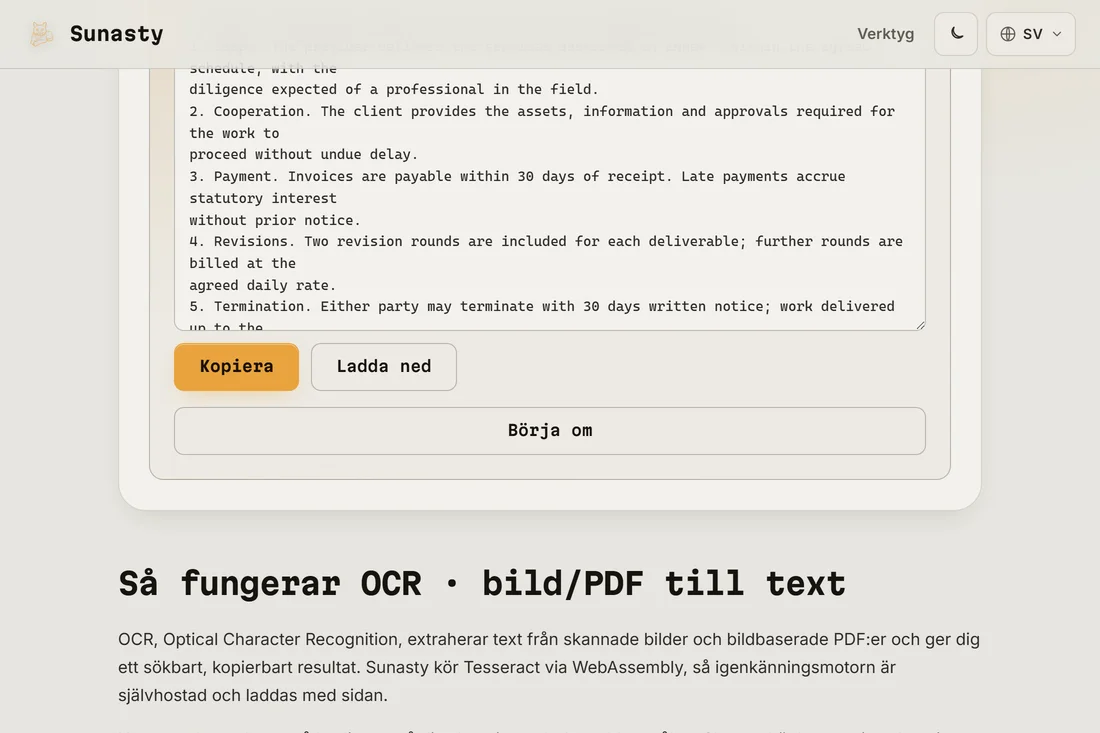
- Klicka på Kör och vänta tills OCR är klar. Motorn (Tesseract, kompilerad till WebAssembly) körs helt och hållet i din webbläsare. Att bearbeta en enda A4-sida tar några sekunder på en modern enhet. Resultatet är en vanlig textfil som du kan ladda ner och kopiera från.
Hur OCR-kvaliteten beror på skanningskvaliteten
OCR-träffsäkerhet domineras av inmatningskvaliteten. En ren skanning i 300 DPI av ett tryckt dokument (utskrift från laserskrivare eller kopiator) ger nästan perfekta resultat. Ett suddigt mobilfoto taget i vinkel i dålig belysning ger ett mycket sämre resultat, med felavlästa tecken, hopslagna ord och saknade rader. Om dina resultat är dåliga, försök förbättra källskanningen: ta fotot rakt framifrån, i bra ljus, och håll sidan plan. PDF-uträtningsverktyget kan räta upp en lätt roterad skanning innan du kör OCR på den.
Vad du gör med den extraherade texten
Utdatan är en vanlig textfil med de igenkända tecknen i läsordning. Du kan klistra in den i ett ordbehandlingsprogram, söka i den, översätta den eller använda den som utgångspunkt för ett redigerat dokument. För en sökbar PDF (den ursprungliga sidbilden med ett osynligt textlager ovanpå) skulle du normalt använda dedikerade skrivbordsprogram som Adobe Acrobat eller OCRmyPDF: verktyget på enheten här ger bara ut vanlig text, vilket är vad de flesta användningsfall faktiskt behöver.
Verktygen som används i den här guiden
- OCR · bild/PDF till text Extrahera text från skannade bilder eller PDF:er helt i din webbläsare, körs offline, ingen uppladdning.
- PDF till bilder Konvertera varje PDF-sida till PNG eller JPG direkt i din webbläsare.
- Komprimera PDF Minska PDF-filens storlek genom förlustfri optimering av dess interna struktur, utan uppladdning.
Vanliga frågor
Laddas min skanning upp till en fjärrserver?
Nej. Tesseract är kompilerat till WebAssembly och körs direkt inuti din webbläsarflik. Språkmodellen (ungefär 4 MB för den snabba engelska modellen) laddas ner från den här sajten en gång och förblir sedan cachad för offlineanvändning. Din fil läses från din lokala disk och bearbetas i minnet: den skickas aldrig till någon server. Detta är särskilt viktigt för skannade avtal, medicinska dokument eller personlig korrespondens.
Varför är OCR-utdatan ofullständig på mitt dokument?
OCR-fel kommer från skanningskvaliteten (låg upplösning, oskärpa, snedställning, skuggor) eller från ovanliga typsnitt och layouter. Prova uträtningsverktyget först om sidan inte är helt rak. För handskriven text faller Tesseracts träffsäkerhet avsevärt: den är tränad på tryckta tecken, inte handstil. För blandade dokument (tryckt text plus en handskriven signatur) kommer de tryckta delarna oftast ut korrekt medan de handskrivna delarna blir förvanskade eller utelämnade.